调用栈
调用栈是一种栈结构(后进先出),在js代码运行的时候会形成一个栈。此后会将全局上下文,函数上下文等等push进入这个栈中,当函数执行完成之后会被pop出该栈.浏览器的调用栈有一个最大的数量,如果超出这个数量的话就会跑出错误.1
2
3
4
5
6function callStack(){
console.log('callStack')
callStack()
}
callStack()
// Uncaught RangeError: Maximum call stack size exceeded以上的递归执行就会超出浏览器的调用栈的最大值,导致当前页面卡死,从而抛出错误.
栈数据结构
栈数据结构是先进后出。类似于我们在桌子上面摆放的书籍,放在最上面的会先被使用,放到最下面的会被等到上面的都被使用之后才会被使用(不考虑从中间抽取)。其结构如下: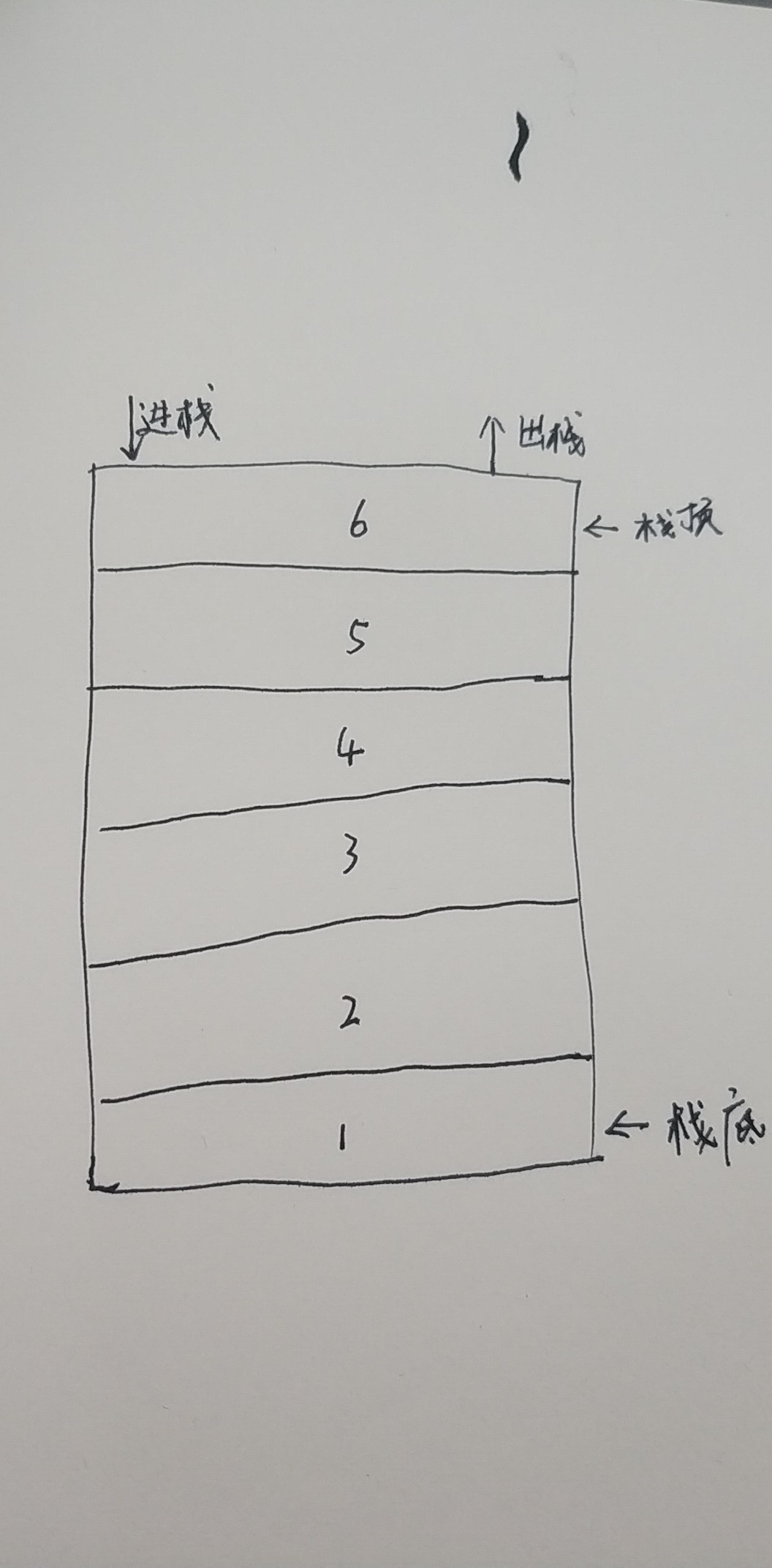
堆数据结构
堆数据结构是一种树状结构,是一种无序的。例如JSON格式中的数据,我们存储的key-value可以是无序的。我们只需要知道key值就可以取出value。而不用关心实际的顺序是怎么样的(思考复合数据类型)。队列结构
队列是一种先进先出的数据结构。先进的会先得到服务,后进的后面才能得到服务。就像我们排队一样。其机构如下: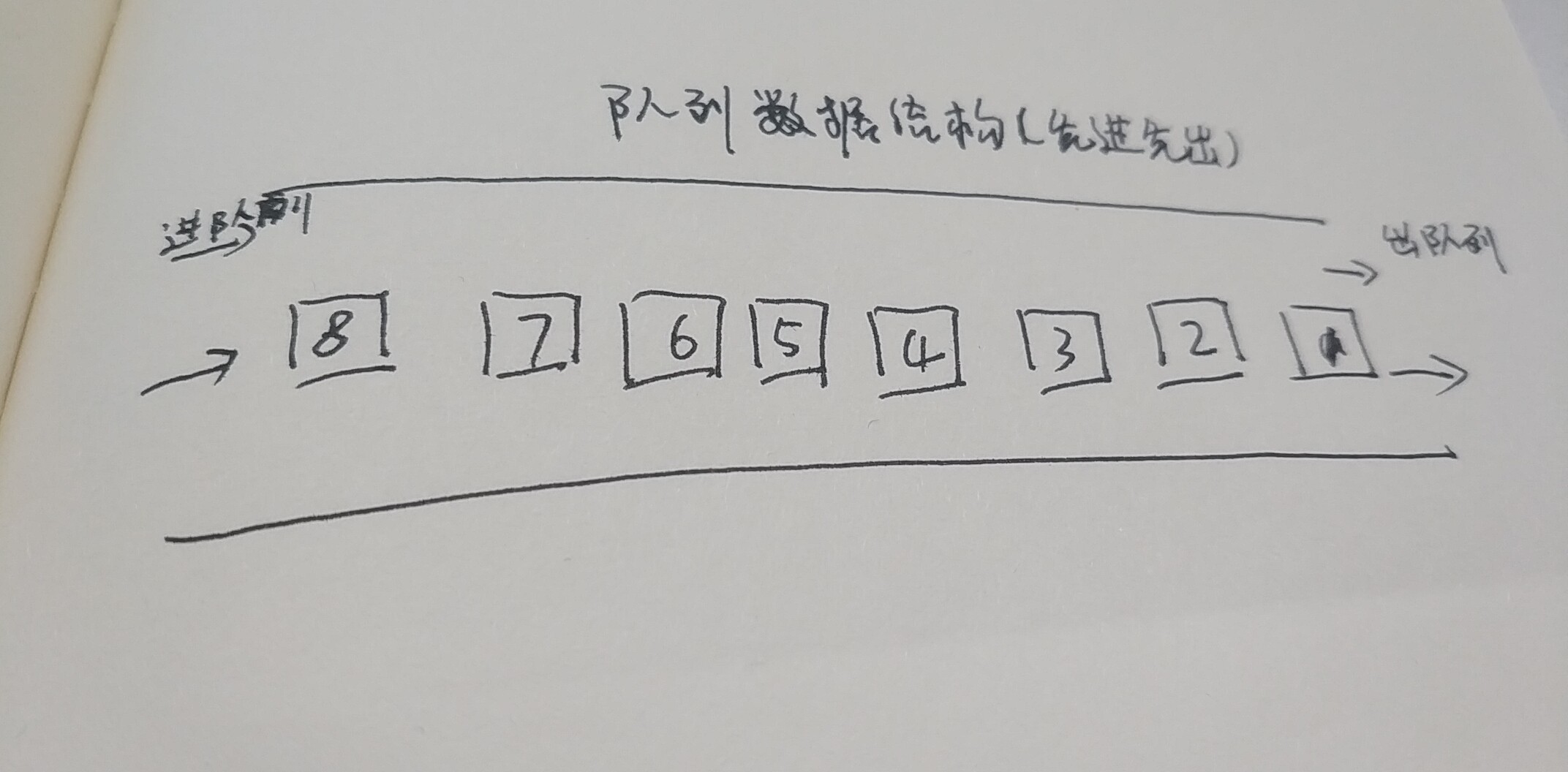
变量的存放
数据是存放在内存中(包含栈、堆、池(也称为常量池存放常量))的,而内存中只存在栈和堆,那么我们声明的变量是存放在堆中还是栈中呢分为两种情况,- 基本数据类型(undefined,null,boolean,number,string,symbol):基本数据类型是将数据直接存储在栈中,因为这些类型在内存中分别占有固定大小的空间,是直接按值类访问的。
- 引用类型(object):保存在堆中,因为这种值的大小不固定,因此不能把它直接放入到栈内存中,但是但是内存地址大小是固定的,因此保存在堆内存中,在栈内存中存放的只是该对象的访问地址。当查询引用类型的变量的时候,先从栈内存中读取到引用类型的内存地址,然后再通过地址栈找到堆中的值。因此这种方式访问叫做按引用访问。
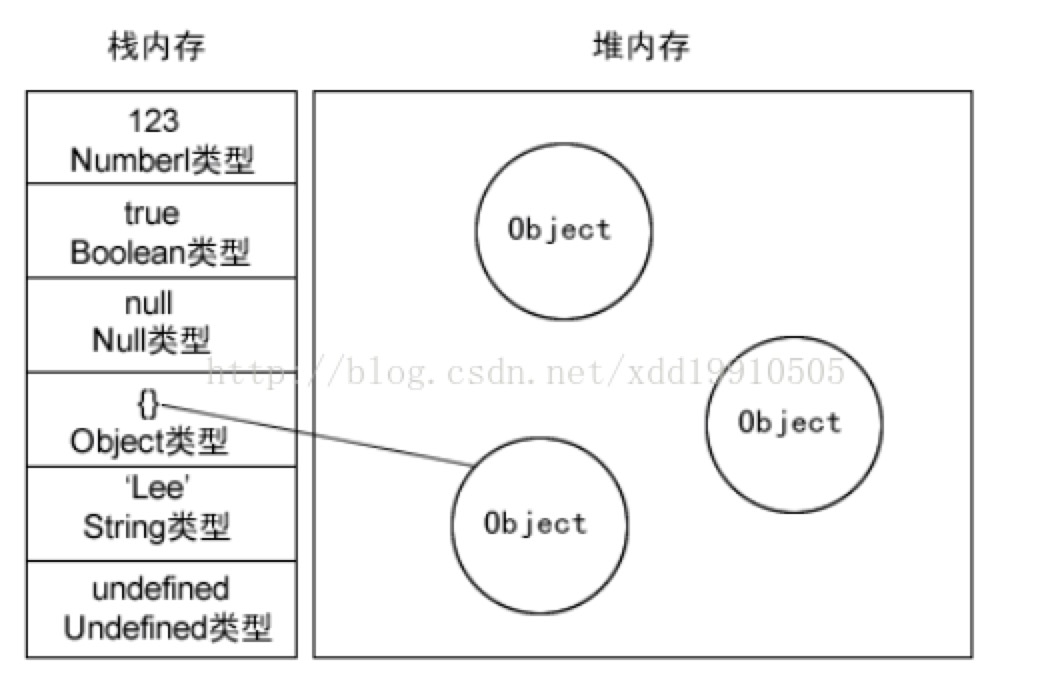
内存空间管理
js的内存生命周期如下:- 分配你所需要的内存
- 使用分配到的内存(读,写)
- 在不需要时将其释放、归还
js拥有自动垃圾收集机制,最常用的是通过标记清除的算法来找到哪些对象是不再继续使用的,使用a=null其实仅仅只是做了一个释放引用的操作,让a原本对应的值失去引用。脱离执行环境,这个值会在下一次垃圾收集器执行操作的时候被找到并释放。
在局部作用域中,当函数执行完毕,局部变量也就没有存在的必要了,因此垃圾收集器很容易做出判断并回收,但是全局什么时候释放内存空间则是很难判断,这也是为什么我们需要尽量少的使用全局变量的原因。
调用堆栈
Last updated:
